Yet another idea of collaboratively edited knowledge base
Question and answer websites
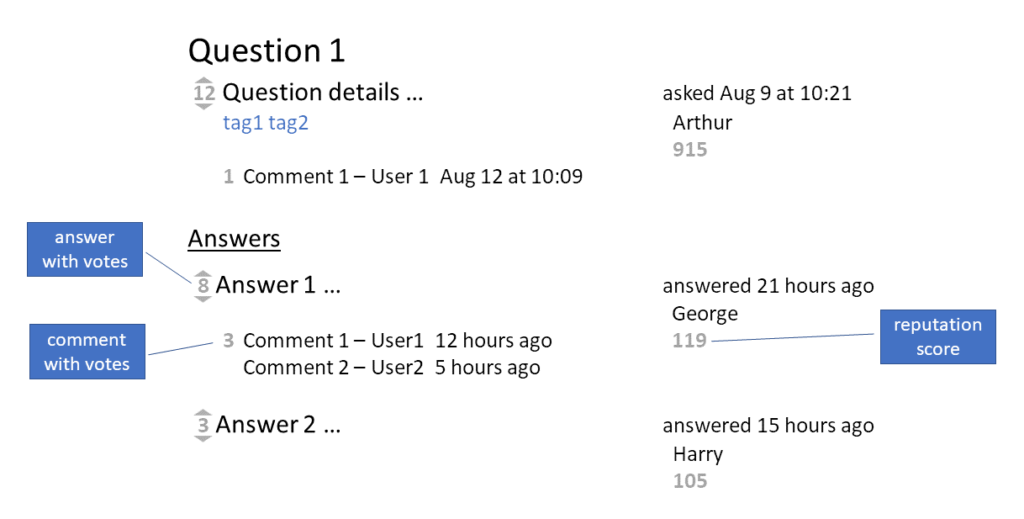
Do you know Quora.com, StackExchange.com, or StackOverflow.com? On each of these websites you can ask questions and get answers. Figure 1 schematically shows the interface of these websites. Questions can be tagged, both questions and answers can be commented. The main advantage compared to internet forums is the ability to vote for or against an answer. Thanks to this, answers can be sorted from the best to the worst [1]. Users earn points for their activity.
Fine-grained analogy
Let’s try to use an analogous interface to build a knowledge base. By a knowledge base I mean a database with reasonably credible information that is easily accessible to both people and computers. To do this, we change a format of a question to this pair: “object/item name [> object/item name] > feature name”, and the text of an answer to the value of this feature. The square brackets indicate that we can optionally specify what part of the object/item we have in mind. So, for many questions instead of asking a question like “What is the resolution of HP ProBook 430 G1 notebook screen?” we can just write: “HP ProBook 430 G1 > Screen > Resolution”. Likewise, instead of adding the answer “HP ProBook 430 G1 notebooks have a screen with 1366×768 resolution”, we can just add the answer “1366×768”.
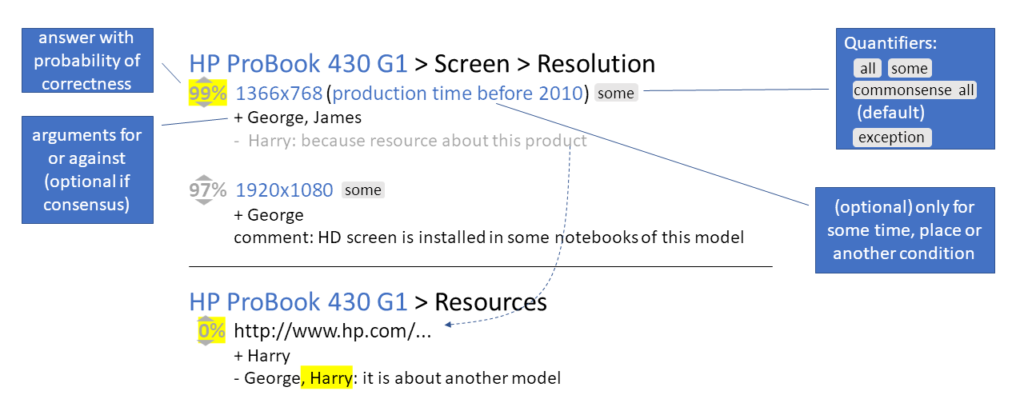
A “question” can have several mutually nonconflicting answers – for example, the aforementioned notebook model has variants that differ in the screen resolution – see figure 2a. Users can vote for or against correctness of a particular answer. Based on these votes, the system estimates probability of its correctness. Answers are also called information because each answer is a piece of information.



Generally, the interface is quite similar to Wikidata - the system used to collect data displayed in Wikipedia infoboxes.
Quantifiers
A user can add one of the following quantifiers to an answer specifying the scope of its validity:
- all - the answer applies to all notebooks of this model
- some - the answer applies to some notebooks of this model
- commonsense all - the answer applies to all notebooks of this model but exceptions are possible
- exception - the answer applies only to unique notebooks of this model (it is the inverse of the "commonsense all" quantifier)
If a question has an answer with the "all" quantifier, then it cannot have another nonconflicting answer. Life often differs from theory, therefore the "commonsense all" quantifier is the default quantifier. Thanks to it, if a question "How many wheels does a passenger car have?" has the answer "4" with no quantifier, it is true even if some passenger cars have a different number of wheels. If a question has an answer with the "commonsense all" quantifier, it may have other nonconflicting answers with the "exception" quantifier. In our notebook example the answers should have the "some" quantifier - they will be nonconflicting with each other.
If a user adds an answer conflicting with other answers, then those who voted for these answers are automatically notified, making the discussion easier and faster.
Limiters
The scope of an answer can also be limited by a text written in brackets. For example, we can state that HP ProBook 430 G1 notebooks with a 1366x768 screen resolution were manufactured before 2010 (see figure 2a) or were available for sale in Europe. This functionality is important because some data can change over time [5].
Discussion
George and James voted for correctness of the answer 1366x768. George and James are credible, thus an algorithm estimated the probability of correctness of this answer to 99% (fig. 2a).
Harry votes against the answer 1366x768. Voting resulting in a lack of consensus should be supported with an argument. Any sentence in a natural language can be the argument, although it is recommended to be expressed as another piece of information stored in the system. Thanks to this, to assess correctness of such argument the system can use the same algorithm that is used to evaluate any other information1. Harry's argument against correctness of the 1366x768 answer is that he found a manufacturer's web page stating that this model has screens only with 1920x1080 resolution. To this end, Harry adds the address of this web page as information about resources describing this notebook model and points this information as an argument against correctness of the answer 1366x768 (fig. 2b). The resources in general can be: photos, videos, and web pages related to an object/item.
After Harry's vote, the credibility of the answer 1366x768 drops from 99% to 60%. George and James are automatically notified about this. Then George notices that this web page describes another notebook model and votes against correctness of the information that this web page is about this model. As a result, credibility of this information drops to 55%, and credibility of the1366x768 answer increases from 60% to 75% (fig. 2c). Harry is automatically notified about this, he notices his mistake and admits to it by voting against the information about this web page. Credibility of the information about the web page drops to 0%, and credibility of the 1366x768 answer returns to 99%, i.e. the original value (fig. 2d). Despite the same credibility of all information as at the beginning there is one difference - Harry's credibility decreased, because he added the incorrect information to the system.
Discussion supported with arguments is an essential part of collaborative knowledge creation [2][6].
1 So a piece of information being an argument for another piece of information can be justified by yet another piece of information. In this way, users can discuss in the system using argument trees.
Credibility of information and users
Probability of information correctness is calculated using credibility of users voting for and against information correctness:
- the more credible users voted for correctness of the information, the greater its credibility;
- the more credible users voted against correctness of the information, the lower its credibility.
If the author of a piece of information is very credible and nobody voted against this information, then it is enough to make this information credible.
Credibility of a user is calculated using probability of information correctness which he voted for and against:
- if a user votes for correctness of the information which will turn out to be correct or votes against correctness of the information which will turn out to be wrong, then it will increase his credibility;
- if a user votes for correctness of the information which will turn out to be wrong or votes against correctness of the information which will turn out to be correct, then it will reduce his credibility.
This bidirectional dependency is analogous to the HITS algorithm, in which hubs correspond to users and authorities correspond to information. Quora uses similar dependency - see PeopleRank, [1] and [3].
Another important element that increases credibility of users and added information is linking users with real people [3]. It can be seen in public - as in Quora, or preferably only by administrators. Quora achieved this by using Facebook accounts to log in users. Another, even stronger, way of linking is to identify a user by his bank account like in PayPal and eBay [4].
Types of information
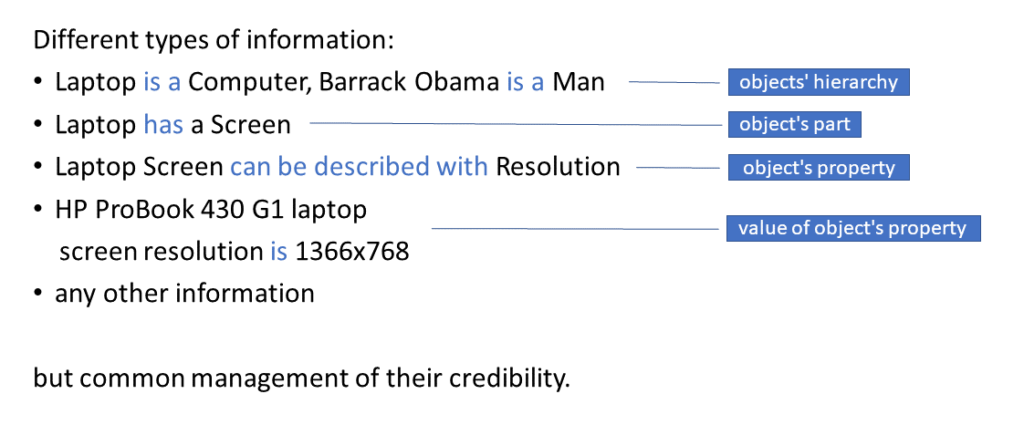
Described methods of answers/information management (i.e. adding answers and assessing their credibility) can be applied to different types of information. So far, I have only shown information about value of object/item property. In general, the system may have the following types of information (fig. 3):
- information about the fact that one object is another object, e.g. a laptop is a computer;
- information that some object contains another object as a part, e.g. a laptop has a computer screen;
- information that an object has some property, e.g. a computer screen has a resolution;
- information that a property of an object has some value, e.g. the resolution of an HP ProBook 430 G1 notebook screen is 1366x768 (the type discussed so far);
- any other information that cannot be presented as one of the 4 previous types - stored as a sentence in a natural language.
Regardless of information type, users can vote for or against its correctness and add arguments in the same way. Credibility of users is taken into account when assessing credibility of information.
The first three types of information allow users to define the structure of objects/items/terms and their properties. Then users can use this structure to determine the value of objects/items/terms properties.
Information overview page
All information about an object/item can be presented on one web page as in figure 4.

The table contains properties of an HP ProBook 430 G1 notebook (3rd type of information) grouped into its parts (2nd type of information). If the value of a property is known (4th type of information), then it is displayed in the second column. Information that HP ProBook 430 G1 is a notebook (1st type of information) is displayed above the table. Below the table there is a list of variants of this notebook model (1st type of information), a list of resources about this model (4th type of information), and other information (of 5th type).
Clicking on any value in the second column of this table redirects to the information detail page as in figure 2. The font color of the information in the second column depends on the probability of its correctness as follows:
| probability of correctness | font color |
| ≥ 99% * (almost certain information) | black |
| 80-99% * (uncertain information) | gray |
| 20-80% * (suspicious information) | orange |
| < 20% * | information is not displayed at all on the overview page |
* - example values
If a property has no value (the cell in the second column of a table is empty) then it can be added directly on the information overview page as in Excel spreadsheet, without going to the information detail page.
When filling in a value of a property, popular answers defined in the notebook object or its parts (e.g. its screen or battery) may be suggested. A notebook has a computer screen. A computer screen was defined to have a technology property with matte and glossy values. When editing a value of the technology property of HP ProBook 430 G1 object we can choose one of these values, although we can use another value if necessary.
The bottom of the information overview page can contain elements added by plugins. For example, there may be a Buy button redirecting users to a store where they can buy the chosen notebook model.
How can we use the described knowledge database?
- We can read information about objects/items on the website (figure 4).
- We can search the database, e.g. find all notebooks with matte 15.6" screen.
- Programmers can add plugins to information overview pages (fig. 4) to extend their functionality, e.g. a plugin adding Buy or Hire button.
- We can work with applications that use specific fields of knowledge - they are described in the posts Shopping advisor and other uses of knowledge base about products and General applications of the knowledge base.
Related concepts and applications:
- collective intelligence - group intelligence that emerges from people collaboration
- argument tree - a visual representation of a structure of arguments; it simplifies reaching consensus in more difficult discussions
- ontology - a computer representation of knowledge
- Wikidata - data used in Wikipedia infoboxes, collected using a method similar to that proposed in this post
[1] Quora: How does the ranking of answers on Quora work?
[2] K. Maleewong, C. Anutariya, V. Wuwongse: SAM: Semantic Argumentation Based Model for Collaborative Knowledge Creation and Sharing System, Proceedings of the 1st International Conference on Computational Collective Intelligence, 2009
[3] Paul Sharoda, Lichan Hong, Ed. H. Chi: Who is authoritative? Understanding reputation mechanisms in Quora, 1st Collective Intelligence Conference, 2012
[4] eBay: Confirming your identity
[5] S. Wallace, L. Van Kleunen, M. Aubin-Le Quere, A. Peterkin, Y. Huang, J. Huang: Drafty: Enlisting Users To Be Editors Who Maintain Structured Data, Proceedings of the 5th Conference on Human Computation and Crowdsourcing, HCOMP 2017
[6] R. Drapeau, L. Chilton, J. Bragg, D. Weld: MicroTalk: Using Argumentation to Improve Crowdsourcing Accuracy, Proceedings of the 4th Conference on Human Computation and Crowdsourcing, HCOMP 2016